
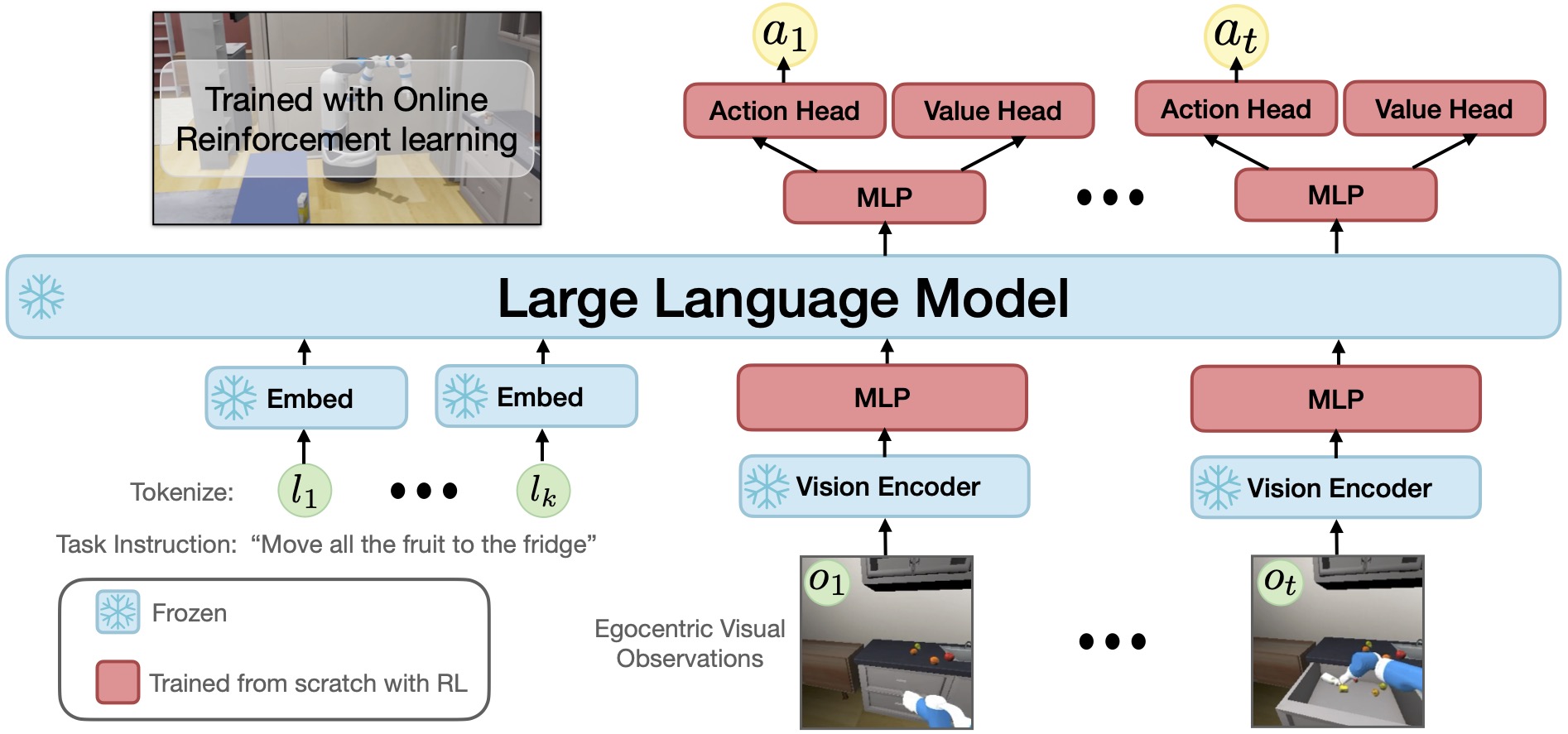
In the new Language Rearrangement benchmark, we show examples of LLaRP successfully zero-shot generalizing to unseen instructions in unseen houses. The agent is trained on 150,000 basic rearrangement instructions. We evaluate to test generalization capabilities with respect to different rearrangement concepts expressed with language. The policy takes as input the task instruction and 1st person RGB head camera (top right of the visualizations), the 3rd person and top down view are only for visualization and not provided to the policy.
In the videos, the LLaRP policy is trained to select high-level action primitives like pick(apple), navigate(table), or close(fridge). These primitives then execute the low-level joint control.
